Overview
salic provides a set of functions to progress from state license data to dashboard summaries. The workflow uses package dplyr (see the dplyr website for an introduction). Loading both packages is recommended:
library(salic)
library(dplyr)
This vignette walks through salic functionality using included sample data. A function reference is available at ?salic.
Standardized License Data
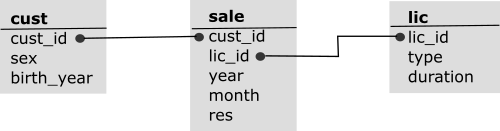
To facilitate a generalized workflow salic is strict about data formatting. For this reason, up-front effort is necessary to standardize the relevant state-level data. However, only 9 variables are needed, and all personally identifiable information can be excluded.
Formatting rules are available at ?cust, ?sale, ?lic. The 3 tables should be related by 2 key columns:
Note that although residency (res) is a customer-level variable, it can change over time; hence the recommended sale-level specification.
Primary Keys
The cust$cust_id and lic$lic_id variables represent primary key columns (i.e., they must uniquely identify rows in the corresponding table):
# check customer ID
length(unique(cust$cust_id)) == nrow(cust)
#> [1] TRUE
# check license ID
length(unique(lic$lic_id)) == nrow(lic)
#> [1] TRUE
Categorical Variables
salic expects specific numeric codes for categorical variables. For example, “sex” must be 1 of 3 values for every customer (1=Male, 2=Female, NA=Unknown):
count(cust, sex)
#> # A tibble: 3 x 2
#> sex n
#> <int> <int>
#> 1 1 21965
#> 2 2 7498
#> 3 NA 537
Sales: year & month
The “year” and “month” variables indicate the date of purchase (1 = Jan, 2 = Feb, etc.).
# sales by month in 2016
filter(sale, year == 2016) %>%
count(year, month)
#> # A tibble: 12 x 3
#> year month n
#> <int> <int> <int>
#> 1 2016 1 205
#> 2 2016 2 289
#> 3 2016 3 943
#> 4 2016 4 904
#> 5 2016 5 799
#> 6 2016 6 1057
#> 7 2016 7 1867
#> 8 2016 8 2205
#> 9 2016 9 2686
#> 10 2016 10 1392
#> 11 2016 11 1180
#> 12 2016 12 539
The month variable is needed for building “mid-year” dashboards, which present a year-to-year view for the first six months of sales.
# count of customers (by year) who purchased in the first 6 months
filter(sale, year > 2015, month <= 6) %>%
distinct(cust_id, year) %>%
count(year)
#> # A tibble: 3 x 2
#> year n
#> <int> <int>
#> 1 2016 3461
#> 2 2017 3490
#> 3 2018 3220
Licenses: type
The license table includes two columns important for customer trending. The “type” column specifies whether a license provides:
- a hunting privilege: “hunt”
- a fishing privilege: “fish”
- or both: “combo”
count(lic, type)
#> # A tibble: 3 x 2
#> type n
#> <chr> <int>
#> 1 combo 18
#> 2 fish 36
#> 3 hunt 82
# count hunters for select years
filter(lic, type %in% c("hunt", "combo")) %>%
inner_join(sale, by = "lic_id") %>%
filter(year > 2015) %>%
distinct(cust_id, year) %>%
count(year)
#> # A tibble: 3 x 2
#> year n
#> <int> <int>
#> 1 2016 2868
#> 2 2017 3008
#> 3 2018 2925
Licenses: duration
The “duration” column is necessary for building a license history. License types can be organized into 3 groups with respect to this variable:
- Multi-years: duration > 1 (2 = 2-year, 3 = 3-year, etc.)
- Lifetimes: duration = 99
- All others: duration = 1
count(lic, duration)
#> # A tibble: 3 x 2
#> duration n
#> <int> <int>
#> 1 1 102
#> 2 3 20
#> 3 99 14
# customers who buy 3-year licenses
cust_3yr <- filter(lic, duration == 3) %>%
inner_join(sale, by = "lic_id") %>%
filter(year > 2015) %>%
distinct(cust_id, year)
count(cust_3yr, year)
#> # A tibble: 3 x 2
#> year n
#> <int> <int>
#> 1 2016 351
#> 2 2017 360
#> 3 2018 371
License History
The presence of multi-year buyers means that an extra step is needed to produce customer trends. This is accomplished by calling rank_sale() and make_history() in sequence.
Ranking Sales
The rank_sale() function is used as a preliminary step to reduce the sale table to 1 row per customer-year. It picks the row with the maximum duration value & optionally includes the earliest month value (for mid-year dashboards).
# all hunting (non-combo) sales in 2016
sale_2016 <- inner_join(
filter(sale, year == 2016),
filter(lic, type == "hunt"),
by = "lic_id"
)
count(sale_2016, duration, year)
#> # A tibble: 3 x 3
#> duration year n
#> <int> <int> <int>
#> 1 1 2016 5786
#> 2 3 2016 19
#> 3 99 2016 4
# ranked hunting (non-combo) sales in 2016
rank_sale(sale_2016) %>%
count(duration, year)
#> # A tibble: 3 x 3
#> duration year n
#> <int> <int> <int>
#> 1 1 2016 2392
#> 2 3 2016 10
#> 3 99 2016 4
Making License History
The make_history() function creates a larger table with 1 row for every year a license is held (i.e., both purchase years and “carried-over” license years are included).
# rank all sales
sale_ranked <- inner_join(sale, lic, by = "lic_id") %>%
rank_sale()
# count customers who purchased licenses
filter(sale_ranked, year %in% 2008:2010) %>%
count(year)
#> # A tibble: 3 x 2
#> year n
#> <int> <int>
#> 1 2008 6393
#> 2 2009 7428
#> 3 2010 7475
# count customers who held licenses
make_history(sale_ranked, 2008:2018) %>%
filter(year %in% 2008:2010) %>%
count(year)
#> # A tibble: 3 x 2
#> year n
#> <int> <int>
#> 1 2008 6393
#> 2 2009 7591
#> 3 2010 7775
Certain variables (e.g., sale$res) need to be included in the “carry_vars” argument of make_history() to ensure inclusion in carried-over license years.
# no residency information is included in the output by default
history <- make_history(sale_ranked, 2008:2018)
names(history)
#> [1] "cust_id" "year" "duration_run" "lapse"
#> [5] "R3"
# include residency
history <- make_history(sale_ranked, 2008:2018, carry_vars = "res")
names(history)
#> [1] "cust_id" "year" "res" "duration_run"
#> [5] "lapse" "R3"
Lapse
A license history table makes it easier to look at customer dynamics over time (e.g., forward: who lapsed?, backward: who is a recruit?). The make_history() function appends 2 measures for this purpose. The “lapse” variable indicates whether a customer held a privilege in the following year (1 = lapsed, 0 = renewed):
# build hunting privilege history
hunt <- filter(lic, type %in% c("hunt", "combo")) %>%
inner_join(sale, by = "lic_id") %>%
rank_sale() %>%
make_history(2008:2018)
# hunters in 2016, what % lapsed (i.e., churned) in 2017?
filter(hunt, year == 2016) %>%
count(year, lapse) %>%
mutate(pct = n / sum(n) * 100)
#> # A tibble: 2 x 4
#> year lapse n pct
#> <int> <int> <int> <dbl>
#> 1 2016 0 3415 81.3
#> 2 2016 1 787 18.7
R3
The R3 measure groups license holders based on how recently they held a license previously:
- Retained (1,2): held a license last year (1: carried over a multi-year license), (2: no carry over)
- Reactivated (3): no license last year, but did hold one within the past 5 years
- Recruited (4): no license held within the previous 5 years
# hunters in 2016, what % are in each R3 group?
filter(hunt, year == 2016) %>%
count(R3) %>%
mutate(pct = n / sum(n) * 100)
#> # A tibble: 4 x 3
#> R3 n pct
#> <int> <int> <dbl>
#> 1 1 1552 36.9
#> 2 2 1737 41.3
#> 3 3 324 7.71
#> 4 4 589 14.0
Note that R3 is set to missing for the first 5 years. This provides a consistent definition of recruitment over time.
filter(hunt, year %in% 2008:2013) %>%
count(year, R3)
#> # A tibble: 9 x 3
#> year R3 n
#> <int> <int> <int>
#> 1 2008 NA 2581
#> 2 2009 NA 3044
#> 3 2010 NA 3234
#> 4 2011 NA 3418
#> 5 2012 NA 3548
#> 6 2013 1 990
#> 7 2013 2 1896
#> 8 2013 3 322
#> 9 2013 4 629
Dashboard Metrics
The license history table provides a flexible data structure for summarizing customer trends. A set of specific summaries are needed for the national/regional dashboard; the following functions are included for this purpose.
Preparation
Some initial preparation is needed to produce the summaries. Functions label_categories() and recode_agecat() are included for this purpose.
data(history)
history <- history %>%
label_categories() %>%
recode_agecat() %>%
filter(!agecat %in% c("0-17", "65+")) %>%
select(cust_id, year, res, sex, agecat, R3, lapse)
# view history for 1 customer
filter(history, cust_id == 6120)
#> # A tibble: 7 x 7
#> cust_id year res sex agecat R3 lapse
#> <int> <int> <fct> <fct> <fct> <fct> <int>
#> 1 6120 2008 Nonresident Male 45-54 <NA> 0
#> 2 6120 2009 Nonresident Male 45-54 <NA> 1
#> 3 6120 2011 Nonresident Male 45-54 <NA> 0
#> 4 6120 2012 Nonresident Male 45-54 <NA> 0
#> 5 6120 2013 Nonresident Male 45-54 Renew 0
#> 6 6120 2014 Nonresident Male 55-64 Renew 0
#> 7 6120 2015 Nonresident Male 55-64 Renew 1
Summarize Participants
The est_part() function produces a simple count of participants by year, either overall or broken out by a segment (e.g., gender).
# overall
part <- est_part(history, "tot")
filter(part, year > 2015)
#> # A tibble: 3 x 3
#> tot year participants
#> <chr> <int> <int>
#> 1 All 2016 7095
#> 2 All 2017 7045
#> 3 All 2018 6701
# by gender
part_sex <- est_part(history, "sex")
filter(part_sex, year > 2015)
#> # A tibble: 6 x 3
#> sex year participants
#> <fct> <int> <int>
#> 1 Male 2016 5485
#> 2 Male 2017 5433
#> 3 Male 2018 5183
#> 4 Female 2016 1496
#> 5 Female 2017 1510
#> 6 Female 2018 1412
Because segments usually contain missing values, the scaleup_part() function is provided to peg segment percentages to total values.
scaleup_part(part_sex, part) %>%
filter(year > 2015)
#> # A tibble: 6 x 3
#> sex year participants
#> <fct> <int> <int>
#> 1 Male 2016 5575
#> 2 Male 2017 5513
#> 3 Male 2018 5266
#> 4 Female 2016 1520
#> 5 Female 2017 1532
#> 6 Female 2018 1435
Summarize Churn
The est_churn(), function summarizes year-to-year turnover.
filter(history, year > 2015) %>%
est_churn("tot")
#> # A tibble: 2 x 3
#> tot year churn
#> <chr> <dbl> <dbl>
#> 1 All 2017 0.481
#> 2 All 2018 0.488
Automating with apply
All of the dashboard summary functions are designed with R’s apply looping functionality in mind:
segments <- c("tot", "res", "sex", "agecat")
# store participant counts in a list of length 4 (1 per segment)
part <- sapply(
segments,
function(i) est_part(history, i, test_threshold = 45),
simplify = FALSE
)
# print the first 2 rows of each segment table
for (i in segments) {
head(part[[i]], 2) %>% print()
cat("\n")
}
#> # A tibble: 2 x 3
#> tot year participants
#> <chr> <int> <int>
#> 1 All 2008 5834
#> 2 All 2009 6775
#>
#> # A tibble: 2 x 3
#> res year participants
#> <fct> <int> <int>
#> 1 Resident 2008 4768
#> 2 Resident 2009 5264
#>
#> # A tibble: 2 x 3
#> sex year participants
#> <fct> <int> <int>
#> 1 Male 2008 4647
#> 2 Male 2009 5391
#>
#> # A tibble: 2 x 3
#> agecat year participants
#> <fct> <int> <int>
#> 1 18-24 2008 709
#> 2 18-24 2009 827